
))
In the Arena: How LMSys changed LLM Benchmarking Forever
Manage episode 448015685 series 3451473
Konten disediakan oleh swyx & Alessio. Semua konten podcast termasuk episode, grafik, dan deskripsi podcast diunggah dan disediakan langsung oleh swyx & Alessio atau mitra platform podcast mereka. Jika Anda yakin seseorang menggunakan karya berhak cipta Anda tanpa izin, Anda dapat mengikuti proses yang diuraikan di sini https://id.player.fm/legal.
Apologies for lower audio quality; we lost recordings and had to use backup tracks.
Our guests today are Anastasios Angelopoulos and Wei-Lin Chiang, leads of Chatbot Arena, fka LMSYS, the crowdsourced AI evaluation platform developed by the LMSys student club at Berkeley, which became the de facto standard for comparing language models. Arena ELO is often more cited than MMLU scores to many folks, and they have attracted >1,000,000 people to cast votes since its launch, leading top model trainers to cite them over their own formal academic benchmarks:
The Limits of Static Benchmarks
We’ve done two benchmarks episodes: Benchmarks 101 and Benchmarks 201. One issue we’ve always brought up with static benchmarks is that 1) many are getting saturated, with models scoring almost perfectly on them 2) they often don’t reflect production use cases, making it hard for developers and users to use them as guidance.
The fundamental challenge in AI evaluation isn't technical - it's philosophical. How do you measure something that increasingly resembles human intelligence? Rather than trying to define intelligence upfront, Arena let users interact naturally with models and collect comparative feedback. It's messy and subjective, but that's precisely the point - it captures the full spectrum of what people actually care about when using AI.
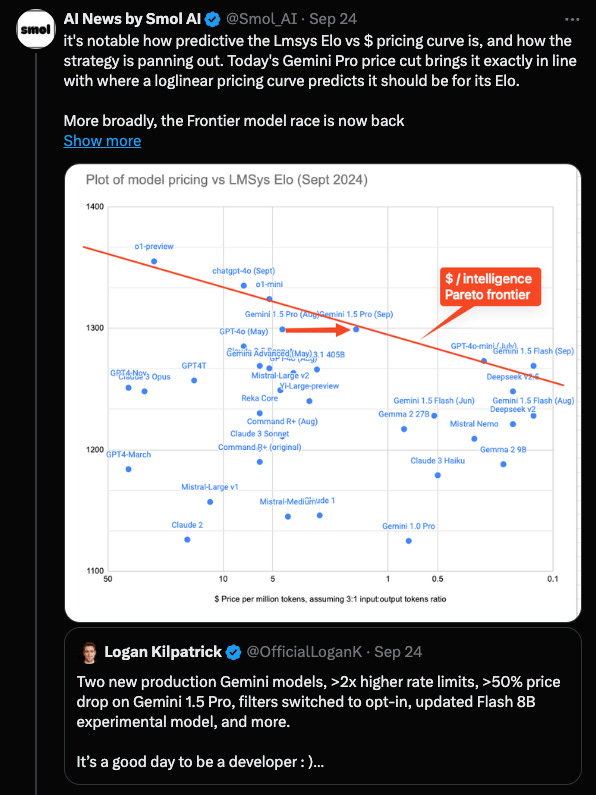
The Pareto Frontier of Cost vs Intelligence
Because the Elo scores are remarkably stable over time, we can put all the chat models on a map against their respective cost to gain a view of at least 3 orders of magnitude of model sizes/costs and observe the remarkable shift in intelligence per dollar over the past year:

This frontier stood remarkably firm through the recent releases of o1-preview and price cuts of Gemini 1.5:
The Statistics of Subjectivity
In our Benchmarks 201 episode, Clémentine Fourrier from HuggingFace thought this design choice was one of shortcomings of arenas: they aren’t reproducible. You don’t know who ranked what and what exactly the outcome was at the time of ranking. That same person might rank the same pair of outputs differently on a different day, or might ask harder questions to better models compared to smaller ones, making it imbalanced.
Another argument that people have brought up is confirmation bias. We know humans prefer longer responses and are swayed by formatting - Rob Mulla from Dreadnode had found some interesting data on this in May:

The approach LMArena is taking is to use logistic regression to decompose human preferences into constituent factors. As Anastasios explains: "We can say what components of style contribute to human preference and how they contribute." By adding these style components as parameters, they can mathematically "suck out" their influence and isolate the core model capabilities.
This extends beyond just style - they can control for any measurable factor: "What if I want to look at the cost adjusted performance? Parameter count? We can ex post facto measure that."
This is one of the most interesting things about Arena: You have a data generation engine which you can clean and turn into leaderboards later. If you wanted to create a leaderboard for poetry writing, you could get existing data from Arena, normalize it by identifying these style components. Whether or not it’s possible to really understand WHAT bias the voters have, that’s a different question.
Private Evals
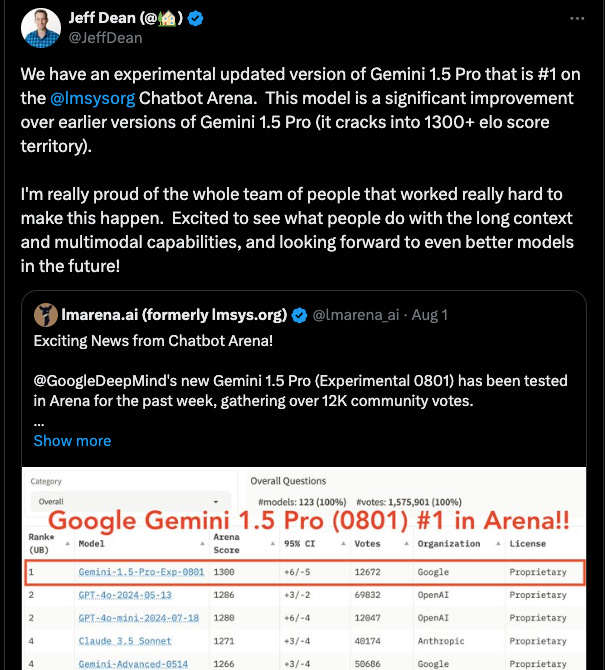
One of the most delicate challenges LMSYS faces is maintaining trust while collaborating with AI labs. The concern is that labs could game the system by testing multiple variants privately and only releasing the best performer. This was brought up when 4o-mini released and it ranked as the second best model on the leaderboard:
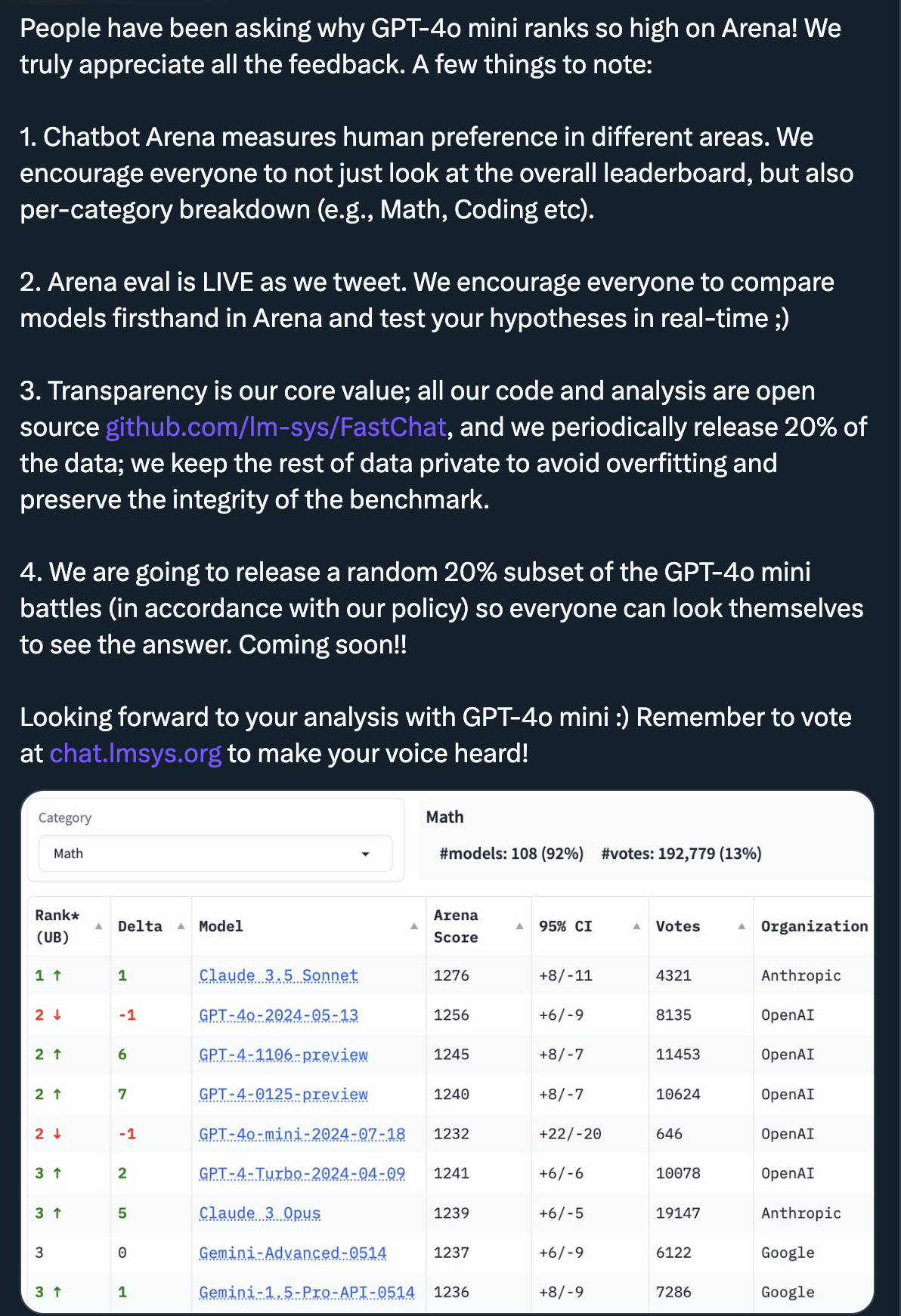
But this fear misunderstands how Arena works. Unlike static benchmarks where selection bias is a major issue, Arena's live nature means any initial bias gets washed out by ongoing evaluation. As Anastasios explains: "In the long run, there's way more fresh data than there is data that was used to compare these five models."
The other big question is WHAT model is actually being tested; as people often talk about on X / Discord, the same endpoint will randomly feel “nerfed” like it happened for “Claude European summer” and corresponding conspiracy theories:
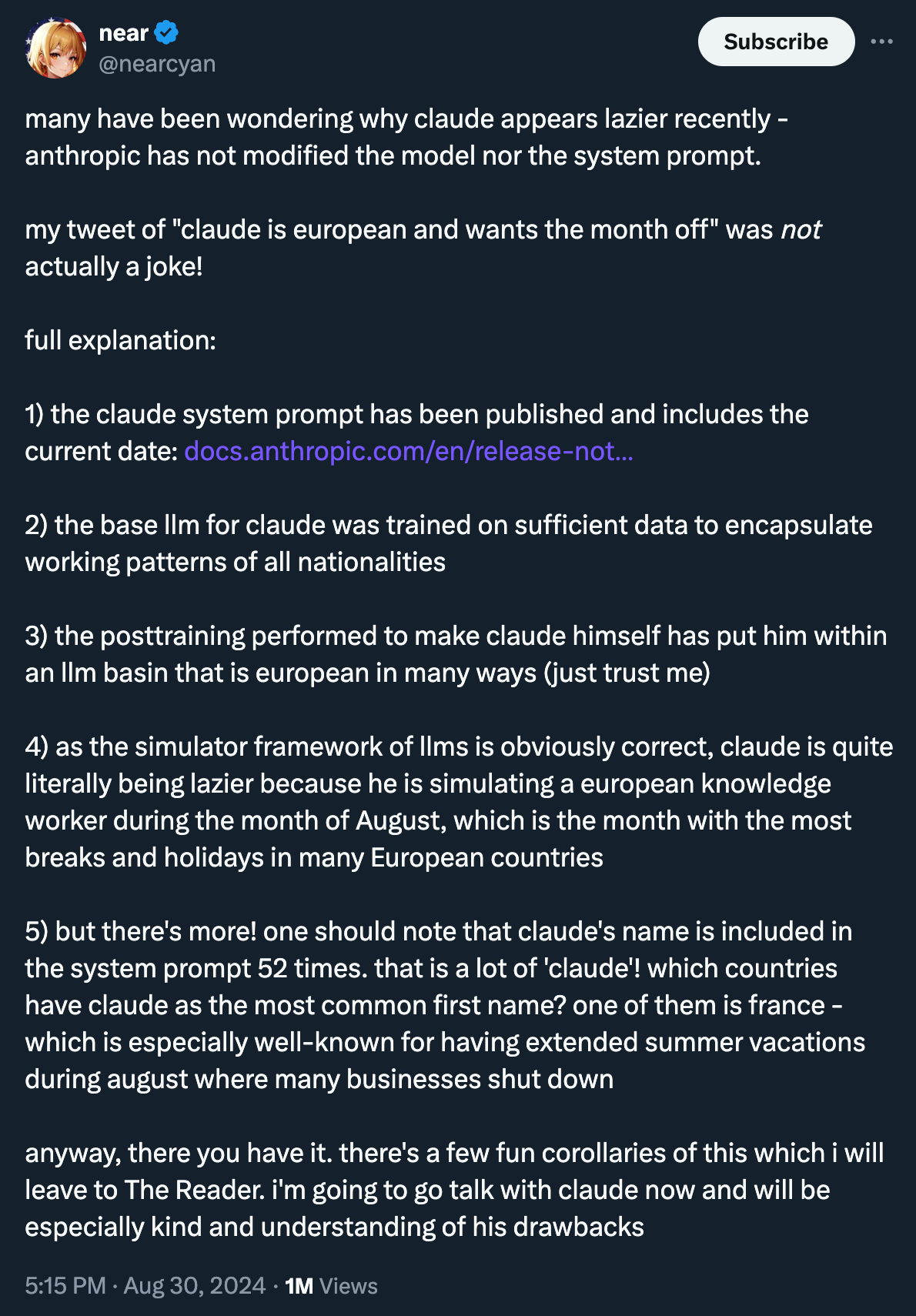
It’s hard to keep track of these performance changes in Arena as these changes (if real…?) are not observable.
The Future of Evaluation
The team's latest work on RouteLLM points to an interesting future where evaluation becomes more granular and task-specific. But they maintain that even simple routing strategies can be powerful - like directing complex queries to larger models while handling simple tasks with smaller ones.
Arena is now going to expand beyond text into multimodal evaluation and specialized domains like code execution and red teaming. But their core insight remains: the best way to evaluate intelligence isn't to simplify it into metrics, but to embrace its complexity and find rigorous ways to analyze it. To go after this vision, they are spinning out Arena from LMSys, which will stay as an academia-driven group at Berkeley.
Full Video Podcast
Chapters
00:00:00 - Introductions
00:01:16 - Origin and development of Chatbot Arena
00:05:41 - Static benchmarks vs. Arenas
00:09:03 - Community building
00:13:32 - Biases in human preference evaluation
00:18:27 - Style Control and Model Categories
00:26:06 - Impact of o1
00:29:15 - Collaborating with AI labs
00:34:51 - RouteLLM and router models
00:38:09 - Future of LMSys / Arena
Show Notes
Anastasios' NeurIPS Paper Conformal Risk Control
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, Partner and CTO in Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai.
Swyx [00:00:14]: Hey, and today we're very happy and excited to welcome Anastasios and Wei Lin from LMSys. Welcome guys.
Wei Lin [00:00:21]: Hey, how's it going? Nice to see you.
Anastasios [00:00:23]: Thanks for having us.
Swyx [00:00:24]: Anastasios, I actually saw you, I think at last year's NeurIPS. You were presenting a paper, which I don't really super understand, but it was some theory paper about how your method was very dominating over other sort of search methods. I don't remember what it was, but I remember that you were a very confident speaker.
Anastasios [00:00:40]: Oh, I totally remember you. Didn't ever connect that, but yes, that's definitely true. Yeah. Nice to see you again.
Swyx [00:00:46]: Yeah. I was frantically looking for the name of your paper and I couldn't find it. Basically I had to cut it because I didn't understand it.
Anastasios [00:00:51]: Is this conformal PID control or was this the online control?
Wei Lin [00:00:55]: Blast from the past, man.
Swyx [00:00:57]: Blast from the past. It's always interesting how NeurIPS and all these academic conferences are sort of six months behind what people are actually doing, but conformal risk control, I would recommend people check it out. I have the recording. I just never published it just because I was like, I don't understand this enough to explain it.
Anastasios [00:01:14]: People won't be interested.
Wei Lin [00:01:15]: It's all good.
Swyx [00:01:16]: But ELO scores, ELO scores are very easy to understand. You guys are responsible for the biggest revolution in language model benchmarking in the last few years. Maybe you guys want to introduce yourselves and maybe tell a little bit of the brief history of LMSys
Wei Lin [00:01:32]: Hey, I'm Wei Lin. I'm a fifth year PhD student at UC Berkeley, working on Chatbot Arena these days, doing crowdsourcing AI benchmarking.
Anastasios [00:01:43]: I'm Anastasios. I'm a sixth year PhD student here at Berkeley. I did most of my PhD on like theoretical statistics and sort of foundations of model evaluation and testing. And now I'm working 150% on this Chatbot Arena stuff. It's great.
Alessio [00:02:00]: And what was the origin of it? How did you come up with the idea? How did you get people to buy in? And then maybe what were one or two of the pivotal moments early on that kind of made it the standard for these things?
Wei Lin [00:02:12]: Yeah, yeah. Chatbot Arena project was started last year in April, May, around that. Before that, we were basically experimenting in a lab how to fine tune a chatbot open source based on the Llama 1 model that I released. At that time, Lama 1 was like a base model and people didn't really know how to fine tune it. So we were doing some explorations. We were inspired by Stanford's Alpaca project. So we basically, yeah, grow a data set from the internet, which is called ShareGPT data set, which is like a dialogue data set between user and chat GPT conversation. It turns out to be like pretty high quality data, dialogue data. So we fine tune on it and then we train it and release the model called V2. And people were very excited about it because it kind of like demonstrate open way model can reach this conversation capability similar to chat GPT. And then we basically release the model with and also build a demo website for the model. People were very excited about it. But during the development, the biggest challenge to us at the time was like, how do we even evaluate it? How do we even argue this model we trained is better than others? And then what's the gap between this open source model that other proprietary offering? At that time, it was like GPT-4 was just announced and it's like Cloud One. What's the difference between them? And then after that, like every week, there's a new model being fine tuned, released. So even until still now, right? And then we have that demo website for V2 now. And then we thought like, okay, maybe we can add a few more of the model as well, like API model as well. And then we quickly realized that people need a tool to compare between different models. So we have like a side by side UI implemented on the website to that people choose, you know, compare. And we quickly realized that maybe we can do something like, like a battle on top of ECLMs, like just anonymize it, anonymize the identity, and that people vote which one is better. So the community decides which one is better, not us, not us arguing, you know, our model is better or what. And that turns out to be like, people are very excited about this idea. And then we tweet, we launch, and that's, yeah, that's April, May. And then it was like first two, three weeks, like just a few hundred thousand views tweet on our launch tweets. And then we have regularly double update weekly, beginning at a time, adding new model GPT-4 as well. So it was like, that was the, you know, the initial.
Anastasios [00:04:58]: Another pivotal moment, just to jump in, would be private models, like the GPT, I'm a little,
Wei Lin [00:05:04]: I'm a little chatty. That was this year. That was this year.
Anastasios [00:05:07]: Huge.
Wei Lin [00:05:08]: That was also huge.
Alessio [00:05:09]: In the beginning, I saw the initial release was May 3rd of the beta board. On April 6, we did a benchmarks 101 episode for a podcast, just kind of talking about, you know, how so much of the data is like in the pre-training corpus and blah, blah, blah. And like the benchmarks are really not what we need to evaluate whether or not a model is good. Why did you not make a benchmark? Maybe at the time, you know, it was just like, Hey, let's just put together a whole bunch of data again, run a, make a score that seems much easier than coming out with a whole website where like users need to vote. Any thoughts behind that?
Wei Lin [00:05:41]: I think it's more like fundamentally, we don't know how to automate this kind of benchmarks when it's more like, you know, conversational, multi-turn, and more open-ended task that may not come with a ground truth. So let's say if you ask a model to help you write an email for you for whatever purpose, there's no ground truth. How do you score them? Or write a story or a creative story or many other things like how we use ChatterBee these days. It's more open-ended. You know, we need human in the loop to give us feedback, which one is better. And I think nuance here is like, sometimes it's also hard for human to give the absolute rating. So that's why we have this kind of pairwise comparison, easier for people to choose which one is better. So from that, we use these pairwise comparison, those to calculate the leaderboard. Yeah. You can add more about this methodology.
Anastasios [00:06:40]: Yeah. I think the point is that, and you guys probably also talked about this at some point, but static benchmarks are intrinsically, to some extent, unable to measure generative model performance. And the reason is because you cannot pre-annotate all the outputs of a generative model. You change the model, it's like the distribution of your data is changing. New labels to deal with that. New labels are great automated labeling, right? Which is why people are pursuing both. And yeah, static benchmarks, they allow you to zoom in to particular types of information like factuality, historical facts. We can build the best benchmark of historical facts, and we will then know that the model is great at historical facts. But ultimately, that's not the only axis, right? And we can build 50 of them, and we can evaluate 50 axes. But it's just so, the problem of generative model evaluation is just so expansive, and it's so subjective, that it's just maybe non-intrinsically impossible, but at least we don't see a way. We didn't see a way of encoding that into a fixed benchmark.
Wei Lin [00:07:47]: But on the other hand, I think there's a challenge where this kind of online dynamic benchmark is more expensive than static benchmark, offline benchmark, where people still need it. Like when they build models, they need static benchmark to track where they are.
Anastasios [00:08:03]: It's not like our benchmark is uniformly better than all other benchmarks, right? It just measures a different kind of performance that has proved to be useful.
Swyx [00:08:14]: You guys also published MTBench as well, which is a static version, let's say, of Chatbot Arena, right? That people can actually use in their development of models.
Wei Lin [00:08:25]: Right. I think one of the reasons we still do this static benchmark, we still wanted to explore, experiment whether we can automate this, because people, eventually, model developers need it to fast iterate their model. So that's why we explored LM as a judge, and ArenaHard, trying to filter, select high-quality data we collected from Chatbot Arena, the high-quality subset, and use that as a question and then automate the judge pipeline, so that people can quickly get high-quality signal, benchmark signals, using this online benchmark.
Swyx [00:09:03]: As a community builder, I'm curious about just the initial early days. Obviously when you offer effectively free A-B testing inference for people, people will come and use your arena. What do you think were the key unlocks for you? Was it funding for this arena? Was it marketing? When people came in, do you see a noticeable skew in the data? Which obviously now you have enough data sets, you can separate things out, like coding and hard prompts, but in the early days, it was just all sorts of things.
Anastasios [00:09:31]: Yeah, maybe one thing to establish at first is that our philosophy has always been to maximize organic use. I think that really does speak to your point, which is, yeah, why do people come? They came to use free LLM inference, right? And also, a lot of users just come to the website to use direct chat, because you can chat with the model for free. And then you could think about it like, hey, let's just be kind of like more on the selfish or conservative or protectionist side and say, no, we're only giving credits for people that battle or so on and so forth. Strategy wouldn't work, right? Because what we're trying to build is like a big funnel, a big funnel that can direct people. And some people are passionate and interested and they battle. And yes, the distribution of the people that do that is different. It's like, as you're pointing out, it's like, that's not as they're enthusiastic.
Wei Lin [00:10:24]: They're early adopters of this technology.
Anastasios [00:10:27]: Or they like games, you know, people like this. And we've run a couple of surveys that indicate this as well, of our user base.
Wei Lin [00:10:36]: We do see a lot of developers come to the site asking polling questions, 20-30%. Yeah, 20-30%.
Anastasios [00:10:42]: It's obviously not reflective of the general population, but it's reflective of some corner of the world of people that really care. And to some extent, maybe that's all right, because those are like the power users. And you know, we're not trying to claim that we represent the world, right? We represent the people that come and vote.
Swyx [00:11:02]: Did you have to do anything marketing-wise? Was anything effective? Did you struggle at all? Was it success from day one?
Wei Lin [00:11:09]: At some point, almost done. Okay. Because as you can imagine, this leaderboard depends on community engagement participation. If no one comes to vote tomorrow, then no leaderboard.
Anastasios [00:11:23]: So we had some period of time when the number of users was just, after the initial launch, it went lower. Yeah. And, you know, at some point, it did not look promising. Actually, I joined the project a couple months in to do the statistical aspects, right? As you can imagine, that's how it kind of hooked into my previous work. At that time, it wasn't like, you know, it definitely wasn't clear that this was like going to be the eval or something. It was just like, oh, this is a cool project. Like Wayland seems awesome, you know, and that's it.
Wei Lin [00:11:56]: Definitely. There's in the beginning, because people don't know us, people don't know what this is for. So we had a hard time. But I think we were lucky enough that we have some initial momentum. And as well as the competition between model providers just becoming, you know, became very intense. Intense. And then that makes the eval onto us, right? Because always number one is number one.
Anastasios [00:12:23]: There's also an element of trust. Our main priority in everything we do is trust. We want to make sure we're doing everything like all the I's are dotted and the T's are crossed and nobody gets unfair treatment and people can see from our profiles and from our previous work and from whatever, you know, we're trustworthy people. We're not like trying to make a buck and we're not trying to become famous off of this or that. It's just, we're trying to provide a great public leaderboard community venture project.
Wei Lin [00:12:51]: Yeah.
Swyx [00:12:52]: Yes. I mean, you are kind of famous now, you know, that's fine. Just to dive in more into biases and, you know, some of this is like statistical control. The classic one for human preference evaluation is humans demonstrably prefer longer contexts or longer outputs, which is actually something that we don't necessarily want. You guys, I think maybe two months ago put out some length control studies. Apart from that, there are just other documented biases. Like, I'd just be interested in your review of what you've learned about biases and maybe a little bit about how you've controlled for them.
Anastasios [00:13:32]: At a very high level, yeah. Humans are biased. Totally agree. Like in various ways. It's not clear whether that's good or bad, you know, we try not to make value judgments about these things. We just try to describe them as they are. And our approach is always as follows. We collect organic data and then we take that data and we mine it to get whatever insights we can get. And, you know, we have many millions of data points that we can now use to extract insights from. Now, one of those insights is to ask the question, what is the effect of style, right? You have a bunch of data, you have votes, people are voting either which way. We have all the conversations. We can say what components of style contribute to human preference and how do they contribute? Now, that's an important question. Why is that an important question? It's important because some people want to see which model would be better if the lengths of the responses were the same, were to be the same, right? People want to see the causal effect of the model's identity controlled for length or controlled for markdown, number of headers, bulleted lists, is the text bold? Some people don't, they just don't care about that. The idea is not to impose the judgment that this is not important, but rather to say ex post facto, can we analyze our data in a way that decouples all the different factors that go into human preference? Now, the way we do this is via statistical regression. That is to say the arena score that we show on our leaderboard is a particular type of linear model, right? It's a linear model that takes, it's a logistic regression that takes model identities and fits them against human preference, right? So it regresses human preference against model identity. What you get at the end of that logistic regression is a parameter vector of coefficients. And when the coefficient is large, it tells you that GPT 4.0 or whatever, very large coefficient, that means it's strong. And that's exactly what we report in the table. It's just the predictive effect of the model identity on the vote. The other thing that you can do is you can take that vector, let's say we have M models, that is an M dimensional vector of coefficients. What you can do is you say, hey, I also want to understand what the effect of length is. So I'll add another entry to that vector, which is trying to predict the vote, right? That tells me the difference in length between two model responses. So we have that for all of our data. We can compute it ex post facto. We added it into the regression and we look at that predictive effect. And then the idea, and this is formally true under certain conditions, not always verifiable ones, but the idea is that adding that extra coefficient to this vector will kind of suck out the predictive power of length and put it into that M plus first coefficient and quote, unquote, de-bias the rest so that the effect of length is not included. And that's what we do in style control. Now we don't just do it for M plus one. We have, you know, five, six different style components that have to do with markdown headers and bulleted lists and so on that we add here. Now, where is this going? You guys see the idea. It's a general methodology. If you have something that's sort of like a nuisance parameter, something that exists and provides predictive value, but you really don't want to estimate that. You want to remove its effect. In causal inference, these things are called like confounders often. What you can do is you can model the effect. You can put them into your model and try to adjust for them. So another one of those things might be cost. You know, what if I want to look at the cost adjusted performance of my model, which models are punching above their weight, parameter count, which models are punching above their weight in terms of parameter count, we can ex post facto measure that. We can do it without introducing anything that compromises the organic nature of the
Wei Lin [00:17:17]: data that we collect.
Anastasios [00:17:18]: Hopefully that answers the question.
Wei Lin [00:17:20]: It does.
Swyx [00:17:21]: So I guess with a background in econometrics, this is super familiar.
Anastasios [00:17:25]: You're probably better at this than me for sure.
Swyx [00:17:27]: Well, I mean, so I used to be, you know, a quantitative trader and so, you know, controlling for multiple effects on stock price is effectively the job. So it's interesting. Obviously the problem is proving causation, which is hard, but you don't have to do that.
Anastasios [00:17:45]: Yes. Yes, that's right. And causal inference is a hard problem and it goes beyond statistics, right? It's like you have to build the right causal model and so on and so forth. But we think that this is a good first step and we're sort of looking forward to learning from more people. You know, there's some good people at Berkeley that work on causal inference for the learning from them on like, what are the really most contemporary techniques that we can use in order to estimate true causal effects if possible.
Swyx [00:18:10]: Maybe we could take a step through the other categories. So style control is a category. It is not a default. I have thought that when you wrote that blog post, actually, I thought it would be the new default because it seems like the most obvious thing to control for. But you also have other categories, you have coding, you have hard prompts. We consider that.
Anastasios [00:18:27]: We're still actively considering it. It's just, you know, once you make that step, once you take that step, you're introducing your opinion and I'm not, you know, why should our opinion be the one? That's kind of a community choice. We could put it to a vote.
Wei Lin [00:18:39]: We could pass.
Anastasios [00:18:40]: Yeah, maybe do a poll. Maybe do a poll.
Swyx [00:18:42]: I don't know. No opinion is an opinion.
Wei Lin [00:18:44]: You know what I mean?
Swyx [00:18:45]: Yeah.
Wei Lin [00:18:46]: There's no neutral choice here.
Swyx [00:18:47]: Yeah. You have all these others. You have instruction following too. What are your favorite categories that you like to talk about? Maybe you tell a little bit of the stories, tell a little bit of like the hard choices that you had to make.
Wei Lin [00:18:57]: Yeah. Yeah. Yeah. I think the, uh, initially the reason why we want to add these new categories is essentially to answer some of the questions from our community, which is we won't have a single leaderboard for everything. So these models behave very differently in different domains. Let's say this model is trend for coding, this model trend for more technical questions and so on. On the other hand, to answer people's question about like, okay, what if all these low quality, you know, because we crowdsource data from the internet, there will be noise. So how do we de-noise? How do we filter out these low quality data effectively? So that was like, you know, some questions we want to answer. So basically we spent a few months, like really diving into these questions to understand how do we filter all these data because these are like medias of data points. And then if you want to re-label yourself, it's possible, but we need to kind of like to automate this kind of data classification pipeline for us to effectively categorize them to different categories, say coding, math, structure, and also harder problems. So that was like, the hope is when we slice the data into these meaningful categories to give people more like better signals, more direct signals, and that's also to clarify what we are actually measuring for, because I think that's the core part of the benchmark. That was the initial motivation. Does that make sense?
Anastasios [00:20:27]: Yeah. Also, I'll just say, this does like get back to the point that the philosophy is to like mine organic, to take organic data and then mine it x plus factor.
Alessio [00:20:35]: Is the data cage-free too, or just organic?
Anastasios [00:20:39]: It's cage-free.
Wei Lin [00:20:40]: No GMO. Yeah. And all of these efforts are like open source, like we open source all of the data cleaning pipeline, filtering pipeline. Yeah.
Swyx [00:20:50]: I love the notebooks you guys publish. Actually really good just for learning statistics.
Wei Lin [00:20:54]: Yeah. I'll share this insights with everyone.
Alessio [00:20:59]: I agree on the initial premise of, Hey, writing an email, writing a story, there's like no ground truth. But I think as you move into like coding and like red teaming, some of these things, there's like kind of like skill levels. So I'm curious how you think about the distribution of skill of the users. Like maybe the top 1% of red teamers is just not participating in the arena. So how do you guys think about adjusting for it? And like feels like this where there's kind of like big differences between the average and the top. Yeah.
Anastasios [00:21:29]: Red teaming, of course, red teaming is quite challenging. So, okay. Moving back. There's definitely like some tasks that are not as subjective that like pairwise human preference feedback is not the only signal that you would want to measure. And to some extent, maybe it's useful, but it may be more useful if you give people better tools. For example, it'd be great if we could execute code with an arena, be fantastic.
Wei Lin [00:21:52]: We want to do it.
Anastasios [00:21:53]: There's also this idea of constructing a user leaderboard. What does that mean? That means some users are better than others. And how do we measure that? How do we quantify that? Hard in chatbot arena, but where it is easier is in red teaming, because in red teaming, there's an explicit game. You're trying to break the model, you either win or you lose. So what you can do is you can say, Hey, what's really happening here is that the models and humans are playing a game against one another. And then you can use the same sort of Bradley Terry methodology with some, some extensions that we came up with in one of you can read one of our recent blog posts for, for the sort of theoretical extensions. You can attribute like strength back to individual players and jointly attribute strength to like the models that are in this jailbreaking game, along with the target tasks, like what types of jailbreaks you want.
Wei Lin [00:22:44]: So yeah.
Anastasios [00:22:45]: And I think that this is, this is a hugely important and interesting avenue that we want to continue researching. We have some initial ideas, but you know, all thoughts are welcome.
Wei Lin [00:22:54]: Yeah.
Alessio [00:22:55]: So first of all, on the code execution, the E2B guys, I'm sure they'll be happy to help
Wei Lin [00:22:59]: you.
Alessio [00:23:00]: I'll please set that up. They're big fans. We're investors in a company called Dreadnought, which we do a lot in AI red teaming. I think to me, the most interesting thing has been, how do you do sure? Like the model jailbreak is one side. We also had Nicola Scarlini from DeepMind on the podcast, and he was talking about, for example, like, you know, context stealing and like a weight stealing. So there's kind of like a lot more that goes around it. I'm curious just how you think about the model and then maybe like the broader system, even with Red Team Arena, you're just focused on like jailbreaking of the model, right? You're not doing kind of like any testing on the more system level thing of the model where like, maybe you can get the training data back, you're going to exfiltrate some of the layers and the weights and things like that.
Wei Lin [00:23:43]: So right now, as you can see, the Red Team Arena is at a very early stage and we are still exploring what could be the potential new games we can introduce to the platform. So the idea is still the same, right? And we build a community driven project platform for people. They can have fun with this website, for sure. That's one thing, and then help everyone to test these models. So one of the aspects you mentioned is stealing secrets, stealing training sets. That could be one, you know, it could be designed as a game. Say, can you still use their credential, you know, we hide, maybe we can hide the credential into system prompts and so on. So there are like a few potential ideas we want to explore for sure. Do you want to add more?
Anastasios [00:24:28]: I think that this is great. This idea is a great one. There's a lot of great ideas in the Red Teaming space. You know, I'm not personally like a Red Teamer. I don't like go around and Red Team models, but there are people that do that and they're awesome. They're super skilled. When I think about the Red Team arena, I think those are really the people that we're building it for. Like, we want to make them excited and happy, build tools that they like. And just like chatbot arena, we'll trust that this will end up being useful for the world. And all these people are, you know, I won't say all these people in this community are actually good hearted, right? They're not doing it because they want to like see the world burn. They're doing it because they like, think it's fun and cool. And yeah. Okay. Maybe they want to see, maybe they want a little bit.
Wei Lin [00:25:13]: I don't know. Majority.
Anastasios [00:25:15]: Yeah.
Wei Lin [00:25:16]: You know what I'm saying.
Anastasios [00:25:17]: So, you know, trying to figure out how to serve them best, I think, I don't know where that fits. I just, I'm not expressing. And give them credits, right?
Wei Lin [00:25:24]: And give them credit.
Anastasios [00:25:25]: Yeah. Yeah. So I'm not trying to express any particular value judgment here as to whether that's the right next step. It's just, that's sort of the way that I think we would think about it.
Swyx [00:25:35]: Yeah. We also talked to Sander Schulhoff of the HackerPrompt competition, and he's pretty interested in Red Teaming at scale. Let's just call it that. You guys maybe want to talk with him.
Wei Lin [00:25:45]: Oh, nice.
Swyx [00:25:46]: We wanted to cover a little, a few topical things and then go into the other stuff that your group is doing. You know, you're not just running Chatbot Arena. We can also talk about the new website and your future plans, but I just wanted to briefly focus on O1. It is the hottest, latest model. Obviously, you guys already have it on the leaderboard. What is the impact of O1 on your evals?
Wei Lin [00:26:06]: Made our interface slower.
Anastasios [00:26:07]: It made it slower.
Swyx [00:26:08]: Yeah.
Wei Lin [00:26:10]: Because it needs like 30, 60 seconds, sometimes even more to, the latency is like higher. So that's one. Sure. But I think we observe very interesting things from this model as well. Like we observe like significant improvement in certain categories, like more technical or math. Yeah.
Anastasios [00:26:32]: I think actually like one takeaway that was encouraging is that I think a lot of people before the O1 release were thinking, oh, like this benchmark is saturated. And why were they thinking that? They were thinking that because there was a bunch of models that were kind of at the same level. They were just kind of like incrementally competing and it sort of wasn't immediately obvious that any of them were any better. Nobody, including any individual person, it's hard to tell. But what O1 did is it was, it's clearly a better model for certain tasks. I mean, I used it for like proving some theorems and you know, there's some theorems that like only I know because I still do a little bit of theory. Right. So it's like, I can go in there and ask like, oh, how would you prove this exact thing? Which I can tell you has never been in the public domain. It'll do it. It's like, what?
Wei Lin [00:27:19]: Okay.
Anastasios [00:27:20]: So there's this model and it crushed the benchmark. You know, it's just like really like a big gap. And what that's telling us is that it's not saturated yet. It's still measuring some signal. That was encouraging. The point, the takeaway is that the benchmark is comparative. There's no absolute number. There's no maximum ELO. It's just like, if you're better than the rest, then you win. I think that was actually quite helpful to us.
Swyx [00:27:46]: I think people were criticizing, I saw some of the academics criticizing it as not apples to apples. Right. Like, because it can take more time to reason, it's basically doing some search, doing some chain of thought that if you actually let the other models do that same thing, they might do better.
Wei Lin [00:28:03]: Absolutely.
Anastasios [00:28:04]: To be clear, none of the leaderboard currently is apples to apples because you have like Gemini Flash, you have, you know, all sorts of tiny models like Lama 8B, like 8B and 405B are not apples to apples.
Wei Lin [00:28:19]: Totally agree. They have different latencies.
Anastasios [00:28:21]: Different latencies.
Wei Lin [00:28:22]: Control for latency. Yeah.
Anastasios [00:28:24]: Latency control. That's another thing. We can do style control, but latency control. You know, things like this are important if you want to understand the trade-offs involved in using AI.
Swyx [00:28:34]: O1 is a developing story. We still haven't seen the full model yet, but it's definitely a very exciting new paradigm. I think one community controversy I just wanted to give you guys space to address is the collaboration between you and the large model labs. People have been suspicious, let's just say, about how they choose to A-B test on you. I'll state the argument and let you respond, which is basically they run like five anonymous models and basically argmax their Elo on LMSYS or chatbot arena, and they release the best one. Right? What has been your end of the controversy? How have you decided to clarify your policy going forward?
Wei Lin [00:29:15]: On a high level, I think our goal here is to build a fast eval for everyone, and including everyone in the community can see the data board and understand, compare the models. More importantly, I think we want to build the best eval also for model builders, like all these frontier labs building models. They're also internally facing a challenge, which is how do they eval the model? That's the reason why we want to partner with all the frontier lab people, and then to help them testing. That's one of the... We want to solve this technical challenge, which is eval. Yeah.
Anastasios [00:29:54]: I mean, ideally, it benefits everyone, right?
Wei Lin [00:29:56]: Yeah.
Anastasios [00:29:57]: And people also are interested in seeing the leading edge of the models. People in the community seem to like that. Oh, there's a new model up. Is this strawberry? People are excited. People are interested. Yeah. And then there's this question that you bring up of, is it actually causing harm?
Wei Lin [00:30:15]: Right?
Anastasios [00:30:16]: Is it causing harm to the benchmark that we are allowing this private testing to happen? Maybe stepping back, why do you have that instinct? The reason why you and others in the community have that instinct is because when you look at something like a benchmark, like an image net, a static benchmark, what happens is that if I give you a million different models that are all slightly different, and I pick the best one, there's something called selection bias that plays in, which is that the performance of the winning model is overstated. This is also sometimes called the winner's curse. And that's because statistical fluctuations in the evaluation, they're driving which model gets selected as the top. So this selection bias can be a problem. Now there's a couple of things that make this benchmark slightly different. So first of all, the selection bias that you include when you're only testing five models is normally empirically small.
Wei Lin [00:31:12]: And that's why we have these confidence intervals constructed.
Anastasios [00:31:16]: That's right. Yeah. Our confidence intervals are actually not multiplicity adjusted. One thing that we could do immediately tomorrow in order to address this concern is if a model provider is testing five models and they want to release one, and we're constructing the models at level one minus alpha, we can just construct the intervals instead at level one minus alpha divided by five. That's called Bonferroni correction. What that'll tell you is that the final performance of the model, the interval that gets constructed, is actually formally correct. We don't do that right now, partially because we know from simulations that the amount of selection bias you incur with these five things is just not huge. It's not huge in comparison to the variability that you get from just regular human voters. So that's one thing. But then the second thing is the benchmark is live, right? So what ends up happening is it'll be a small magnitude, but even if you suffer from the winner's curse after testing these five models, what'll happen is that over time, because we're getting new data, it'll get adjusted down. So if there's any bias that gets introduced at that stage, in the long run, it actually doesn't matter. Because asymptotically, basically in the long run, there's way more fresh data than there is data that was used to compare these five models against these private models.
Swyx [00:32:35]: The announcement effect is only just the first phase and it has a long tail.
Anastasios [00:32:39]: Yeah, that's right. And it sort of like automatically corrects itself for this selection adjustment.
Swyx [00:32:45]: Every month, I do a little chart of Ellim's ELO versus cost, just to track the price per dollar, the amount of like, how much money do I have to pay for one incremental point in ELO? And so I actually observe an interesting stability in most of the ELO numbers, except for some of them. For example, GPT-4-O August has fallen from 12.90𝑡𝑜12.90to12.60 over the past few months. And it's surprising.
Wei Lin [00:33:11]: You're saying like a new version of GPT-4-O versus the version in May?
Swyx [00:33:17]: There was May. May is $12.85. I could have made some data entry error, but it'd be interesting to track these things over time. Anyway, I observed like numbers go up, numbers go down. It's remarkably stable. Gotcha.
Anastasios [00:33:28]: So there are two different track points and the ELO has fallen.
Wei Lin [00:33:31]: Yes.
Swyx [00:33:32]: And sometimes ELOs rise as well. I think a core rose from 1,200𝑡𝑜1,200to1,230. And that's one of the things, by the way, the community is always suspicious about, like, hey, did this same endpoint get dumber after release? Right? It's such a meme.
Anastasios [00:33:45]: That's funny. But those are different endpoints, right?
Wei Lin [00:33:47]: Yeah, those are different API endpoints, I think. For GPT-4-O, August and May. But if it's for like, you know, endpoint versions we fixed, usually we observe small variation after release.
Anastasios [00:34:04]: I mean, you can quantify the variations that you would expect in an ELO. That's a close form number that you can calculate. So if the variations are larger than we would expect, then that indicates that we should
Wei Lin [00:34:17]: look into that. For sure.
Anastasios [00:34:19]: That's important for us to know. So maybe you should send us a reply. Yeah, please.
Wei Lin [00:34:22]: I'll send you some data. Yeah.
Alessio [00:34:24]: And I know we only got a few minutes before we wrap, but there are two things I would definitely love to talk about. One is route LLM. So talking about models, maybe getting dumber over time, blah, blah, blah. Are routers actually helpful in your experience? And Sean pointed out that MOEs are technically routers too. So how do you kind of think about the router being part of the model versus routing different models? And yeah, overall learnings from building it?
Wei Lin [00:34:51]: Yeah. So route LLM is a project we released a few months ago, I think. And our goal was to basically understand, can we use the preference data we collect to route model based on the question, conditional on the questions, because we will make assumption that some model are good at math, some model are good at coding, things like that. So we found it somewhat useful. For sure, this is like ongoing effort. Our first phase with this project is pretty much like open source, the framework that we develop. So for anyone interested in this problem, they can use the framework, and then they can train their own router model, and then to do evaluation to benchmark. So that's our goal, the reason why we released this framework. And I think there are a couple of future stuff we are thinking. One is, can we just scale this, do even more data, even more preference data, and then train a reward model, train like a router model, better router model. Another thing is, release a benchmark, because right now, currently, there seems to be, one of the end point when we developed this project was like, there's just no good benchmark for a router. So that will be another thing we think could be a useful contribution to community. And there's still, for sure, methodology, new methodology we can use.
Swyx [00:36:18]: I think my fundamental philosophical doubt is, does the router model have to be at least as smart as the smartest model? What's the minimum required intelligence of a router model, right? Like, if it's too dumb, it's not going to route properly.
Anastasios [00:36:32]: Well, I think that you can build a very, very simple router that is very effective. So let me give you an example. You can build a great router with one parameter, and the parameter is just like, I'm going to check if my question is hard. And if it's hard, then I'm going to go to the big model. If it's easy, I'm going to go to the little model. You know, there's various ways of measuring hard that are like, pretty trivial, right? Like, does it have code? Does it have math? Is it long? That's already a great first step, right? Because ultimately, at the end of the day, you're competing with a weak baseline, which is any individual model. And you're trying to ask the question, how do I improve cost? And that's like a one-dimensional trade-off. It's like performance cost, and it's great. Now, you can also get into the extension, which is what models are good at what particular
Wei Lin [00:37:23]: types of queries.
Anastasios [00:37:25]: And then, you know, I think your concern starts taking into effect is, can we actually do that? Can we estimate which models are good in which parts of the space in a way that doesn't introduce more variability and more variation and error into our final pipeline than just using the best of them? That's kind of how I see it.
Swyx [00:37:44]: Your approach is really interesting compared to the commercial approaches where you use information from the chat arena to inform your model, which is, I mean, smart, and it's the foundation of everything you do. Yep.
Alessio [00:37:56]: As we wrap, can we just talk about LMSYS and what that's going to be going forward? Like, LMRENA, I'm becoming something. I saw you announced yesterday you're graduating. I think maybe that was confusing since you're PhD students, but this is a different type
Wei Lin [00:38:09]: of graduation.
Anastasios [00:38:10]: Just for context, LMSYS started as like a student club.
Wei Lin [00:38:15]: Student driven. Yeah.
Anastasios [00:38:16]: Student driven, like research projects, you know, many different research projects are part of LMSYS. Sort of chatbot arena has, of course, like kind of become its own thing. And Lianmin and Ying, who are, you know, created LMSYS, have kind of like moved on to working on SGLANG. And now they're doing other projects that are sort of originated from LMSYS. And for that reason, we thought it made sense to kind of decouple the two. Just so, A, the LMSYS thing, it's not like when someone says LMSYS, they think of chatbot arena. That's not fair, so to speak.
Wei Lin [00:38:52]: And we want to support new projects.
Anastasios [00:38:54]: And we want to support new projects and so on and so forth. But of course, these are all like, you know, our friends.
Wei Lin [00:38:59]: So that's why we call it graduation. I agree.
Alessio [00:39:03]: That's like one thing that people wear. Maybe a little confused by where LMSYS kind of starts and ends and where arena starts
Wei Lin [00:39:10]: and ends.
Alessio [00:39:10]: So I think you reach escape velocity now that you're kind of like your own thing.
Swyx [00:39:15]: So I have one parting question. Like, what do you want more of? Like, what do you want people to approach you with?
Anastasios [00:39:21]: Oh, my God, we need so much help. One thing would be like, we're obviously expanding into like other kinds of arenas, right? We definitely need like active help on red teaming. We definitely need active help on our different modalities, different modalities.
Wei Lin [00:39:35]: So pilot, yeah, coding, coding.
Anastasios [00:39:38]: You know, if somebody could like help us implement this, like REPL in REPL in chatbot arena,
Wei Lin [00:39:44]: massive, that would be a massive delta.
Anastasios [00:39:45]: And I know that there's people out there who are passionate and capable of doing it. It's just, we don't have enough hands on deck. We're just like an academic research lab, right? We're not equipped to support this kind of project. So, yeah, we need help with that. We also need just like general back-end dev. And new ideas, new conceptual ideas. I mean, honestly, the work that we do spans everything from like foundational statistics, like new proofs to full stack dev. And like anybody who's like, wants to contribute something to that pipeline is, should definitely reach out.
Wei Lin [00:40:22]: We need it. And it's an open source project anyways. Anyone can make a PR.
Anastasios [00:40:26]: And we're happy to, you know, whoever wants to contribute, we'll give them credit, you know? We're not trying to keep all the credit for ourselves. We want it to be a community project.
Wei Lin [00:40:33]: That's great.
Alessio [00:40:34]: And fits this pair of everything you've been doing over there. So, awesome, guys. Well, thank you so much for taking the time. And we'll put all the links in the show notes so that people can find you and reach out if they need it. Thank you so much.
Anastasios [00:40:46]: It's very nice to talk to you. And thank you for the wonderful questions.
Wei Lin [00:40:49]: Thank you so much.
95 episode



